
「数据会说谎」的真实例子有哪些?
日期:2023-08-14 15:42 | 人气:
究竟是数据在说谎,还是逻辑在说谎?最好是你遇到的真实案例,你是如何判断数据表明的错误的?
存活者偏差
二战时英国皇家空军邀请美国的统计学家分析德国地面炮火击中联军轰炸机的资料,并且从专业的角度,建议机体装甲应该如何加强,才能降低被炮火击落的机会。但依照当时的航空技术,机体装甲只能局部加强,否则机体过重,会导致起飞困难及操控迟钝。
统计学家将联军轰炸机的弹着点资料,描绘成两张比较表,研究发现,机翼是最容易被击中的部位, 而飞行员的座舱与机尾,则是最少被击中的部位。
作战指挥官由此认为,应该加强机翼的防护,因为分析表明,那里"密密麻麻都是弹孔,最容易被击中"。但是统计学家却有不同观点,他建议加强座舱与机尾部位的装甲,那儿最少发现弹孔-----因为他的统计样本是联军返航的受损飞机,说明大多数被击中飞行员座舱和尾部发动机的飞机,根本没法返航就坠毁了。
所以如LS几位所答,不是数据说谎,而是没注意到沉默的数据(缺少了的样本),需要分析者有足够广的视角和逻辑,才能从数据里挖掘出足够正确的东西。
Numbers don't lie.
最近发现大家对如何成为一名数据科学家?的答案比较关注,表示受宠若惊。最近有点小忙,但作为一名DMer鄙人决定继续分享一些知识来回报各位厚爱。下面是看统计报告时要注意的点。
一、数据来源如何说谎
最简单的层级,在查阅统计报告之前首先应该关注的是报告出处以及数据来源。以工业品和消费品为例主要的数据来源如下所示:
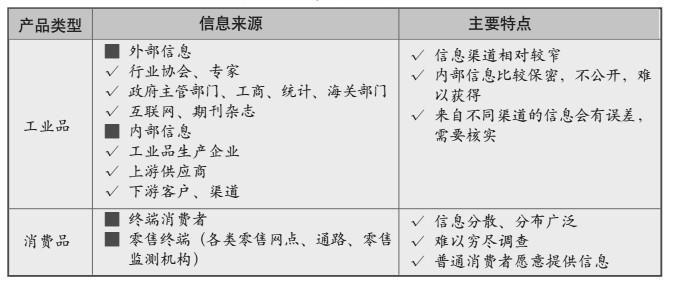
关于数据的来源我们需要注意四点:
(1).数据发布机构是否权威?(代表性)
网上主流的数据资源太多,以下列举一些,不一而足。
- 国研网:行研报告,各类数据(需要付费T T)。
- 国家统计局数据库:宏观数据、金融、教育、行业数据等,包含国家一级、31个省以及200多个市的数据。
- 《中国统计年鉴》:历年统计年鉴以及普查数据、专题数据等。
- United Nations Statistics Division:联合国数据库
- Data | The World Bank: 世界银行数据库
- Federal Reserve Economic Data:美联储数据库
- Socioeconomic Data and Applications Center:美国航空航天局NASA的地球观测系统数据
(2).是否是发布机构原版文件?(可信度)
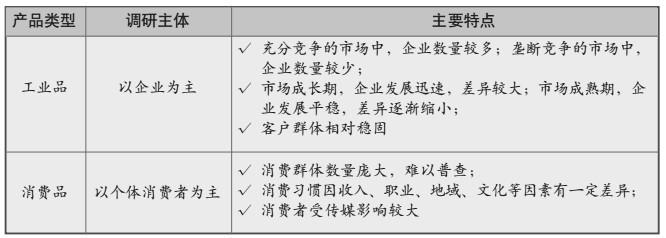
(3).数据采集面向的对象?(调研主体)
举例说明。产品可分为工业类产品和消费类产品,它们在基本属性、购买特征、营销理念等方面有本质的不同,所以需要调研的主体不同。
- 工业类产品:供需双方一般都是企业,需要了解总产值、总产量、销售总额、销售总量,所以调研主体以企业为主。
- 消费类产品:面向大众消费者,统计口径一般是零售市场消费总量、总额,所以调研主体以个体消费者为主。
(4).数据是一手数据还是二手数据?(时效性,相关性)
- 一手数据(Primary data):也称原始数据。指通过人员访谈、询问、问卷、测定等方式直截获得的,时效性和相关性更好。
- 二手数据(Secondary data):利用文献,统计年报以及数据库等前人统计好的数据资料。优点是获取成本低,且现成可用。一般可以长时间保存,生成数据趋势图方便。
栗子:研究人员希望了解工人在遇到工伤后返回工作的情况。
- 一手数据:通过电话采访工人,询问他们多久时间能回到工作、以及返回到工作流程等问题。研究人员得出结论,包括返回到工作流程包括提供优惠住宿,以及为什么一些工人拒绝了这样的提议。
- 二手数据:包括政府,企业的健康和安全记录,例如工人的受伤率,以及工人在国内不同行业的数据。研究人员发现了工伤索赔额度与全职工人工资额度之间的数量关系。
最后将两个数据源相结合,研究人员便能够找到那些能够让受伤的工人愿意马上回到岗位的因素。
通过例子可以看出,一手数据提能够提供量身定制的信息,但往往是需要很长的时间以及昂贵的成本。二手数据通常是能够廉价的取得,而且可在更短的时间内进行分析,但由于数据获取的初始目的可能与研究目的不相关,需要梳理信息来提取您要找的内容。数据研究人员选择的类型时候应该考虑很多因素,包括所研究的问题,预算,技术和可用资源。基于这些因素的影响,他们可能会选择使用一手数据或二手数据,甚至两者兼备。
(5).数据采集方式是什么?(投票方式)
在网络上进行投票还是在现实中分发问卷有很大的不同,两者都有很多细节点需要注意。
- 网络投票:如何防止机器人,恶意投票以及UI的设计是关键。可以参考推荐系统的用户反馈设计。
- 现实问卷:如何设计题目(逻辑性、完整性、非诱导性)以及投放方式(时间、地点、对象)是关键。可以参考调查问卷的设计与评估 (豆瓣)。
二、数据统计如何说谎
数据统计中常常会出现的谎言,这是因为虽然原始的数据相同,但是数据处理的过程不同。具体情况通常可分为四种:抽样方法、样本选取、离群值处理及统计指标设置。
(1).抽样方法的区别
整体样本的维度,粒度和取数逻辑相同的情况下,不用的样本抽样规则会使数据看来更符合或不符合“预期”,从而实现特殊目的。我们知道最基本的定量研究的抽样方法分为两类,一类为非概率抽样,一类为概率抽样。其中概率抽样方法分为四种:
- 随机抽样(Simple random sampling)
方法:将调查总体的观察单位全部编号,再随机抽取部分观察单位组成样本。
优点:操作简单,均数及相应的标准误计算简单。
缺点:总体较大时,难以一一编号。
- 系统抽样(Systematic sampling,又名机械抽样、等距抽样)
方法:先将总体的观察单位按某一顺序号分成N个部分,再从第一部分随机抽取第k号观察单位,然后依次使用相等间距,从每一部分各抽取一个观察单位组成样本。
优点:易于理解、简便易行。
缺点:总体有周期或增减趋势时,易产生偏差。
- 整群抽样(Cluster sampling,整体抽样)
方法:总体分群,再随机抽取几个群组成样本,群内全部调查。
优点:便于组织、节省经费。
缺点:抽样误差大于单纯随机抽样。
- 分层抽样(Stratified sampling)
方法:找到对观察指标影响较大的某种特征,从而将总体分为若干个类别,再从每一层内随机抽取一定数量的观察单位,合起来组成样本。有按比例分配和最优分配两种方案。
优点:样本代表性好,抽样误差减少。
缺点:抽样过程繁杂。
各种抽样方法的抽样误差一般是:整群抽样≥单纯随机抽样≥系统抽样≥分层抽样。
栗子1:在建立客户流失模型时,使用分层抽样。假如两次调研的抽样样本分别是最近一年未消费流量的客户和最近一年未消费流量但经常收发短信的客户,不用做测试基本上就可以确定后者的流失可能性更小。而如果使用随机抽样则很难得出上述结论,所以数据抽样方法的选择对结论影响较大,实际操作时具体需要深入到SQL查询逻辑的研究。
栗子2:普林斯顿大学的信息技术政策中心(CITP)和北卡罗莱纳州大学教堂山分校(University of North Carolina at Chapel Hill)在2013年发表了一篇文章《Big Data: Pitfalls, Methods and Concepts for an Emergent Field:大数据:一个新兴领域的陷阱、方法和概念》。通过实验对一些市场营销人员发出警告:请首先确认抽样的方法是否能够真正地覆盖的整个市场,不要对从社交媒体渠道(如Twitter和Facebook)收集的消费者数据过于自信。
1.Inadequate attention to the implicit and explicit structural biases of the platform(s) most frequently used to generate datasets (the model organism problem).
2.The common practice of selecting on the dependent variable without corresponding attention to the complications of this path.
3.Lack of clarity with regard to sampling, universe and representativeness (the denominator problem).
4.Most big data analyses come from a single platform (hence missing the ecology of information flows).
作者Zeynep Tufekci(博客地址:technosociology,北卡罗来纳大学教授)通过描述对果蝇进行生物测试的方法,质疑很大程度上依赖社会化媒体形成的大数据方法论。大多数的大数据集(Big datasets)研究只包含“节点到节点”(Node-to-node)之间的信息互动;然而面对社会中的群体性事件,无论是通过经验分享或通过广播媒体传播,“场”(Field)效应的地位更加重要。一个典型营销活动(Twitter、Facebook上)的用户参与百分比只有10%,只代表一定的细分市场,可能扭曲调查结果。这些市场调差报告不能准确反映市场的数据,所以无法据此制定出可靠的未来计划。
(2).样本选取的区别
从严格意义上来说统计范围的选择问题并不一定是故意欺骗,因为在数据采集的实践中确实存在样本量失衡的情况,如果遇到这种情况一般使用欠抽样(Under-sampling)和过抽样(Oversampling)进行样本平衡。通常来说样本的问题主要分为以下三种情况:
- 样本抽取的数量。这一点很容易理解,数据样本量差距越大,可比性越小。尤其是在样本分布不均时,数据结果可信度低。
- 样本抽取的主体。为了制造某种统计结果而故意选择对结果有利的样本主体。如针对农村用户和城市用户统计某手机市场占有率,后者结果肯定优于前者。
- 样本抽取的客观环境。比如做运营商网站用户体验分析(User Experience,简称UE),ISO 9241-210标准中对用户体验的定义有如下补充说明:用户体验,即用户在使用一个产品或系统之前、使用期间和使用之后的全部感受,包括情感、信仰、喜好、认知印象、生理和心理反应、行为和成就等各个方面。三个影响用户体验的因素:系统,用户和使用环境。如果测试方法都没有完全相同的客观环境,即使选的是相同样本和用户,分析结果可信度依然较低。
更多资料推荐:
Sampling (豆瓣)(豆瓣版本老,现在有09年新版)
(3).离群值处理方法的区别
离群值(Outlier,异常值):指样本中的个别值,其数值明显偏离其所属样本的其余观测值。
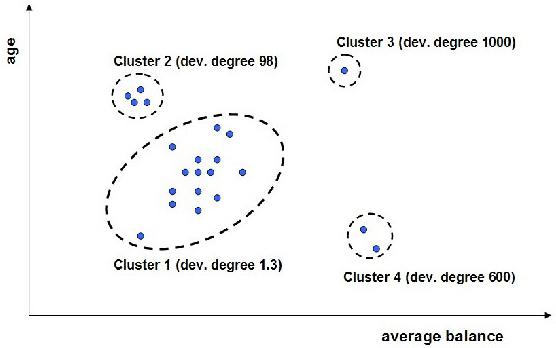
离群值与非离群值之间并没有明显的区别。实际上,用户必须指定一个阈值,以便界定离群值。偏差度高于这个阈值的所有集群被标记为离群值集群,它们的成员都是离群值。如上图中所示。如果设定阈值600,则Cluster3为离群值。
目前对离群值(Outlier)的判别与过滤主要采用两种方法:物理判别法和统计判别法。
- 物理判别法:根据人们对客观事物已有的认识来判别由于外界干扰、人为误差等原因造成实测数据值偏离正常结果。
- 统计判别法:给定一个置信概率,并确定一个置信限,凡是超过此限的误差我们就认为它不属于随机误差范围,将其视为异常值过滤。
通常面对样本时需要做整体数据观察,以确认样本数量、均值、极值、方差、标准差以及数据范围等。极值很可能是离群值,此时如何处理离群值会直接影响数据结果。
栗子:某一周的手机销售数据中,存在异常下单行为导致某一品类的销售额和转化率异常高。如果数据分析师选择忽视该情况,结论就是该手机非常热销抓紧供货,但实际情况并非如此。通常需要把会把离群值拿出来,单独做文字说明。
(4).统计指标的区别
数据统计的业务指标成百上千,根据不同目的选择合适的指标组合,就能实现说谎的效果。
我们都知道,平均数是表示一组数据集中趋势的量数,它是反映数据集中趋势的一项指标。解答平均数应用题的关键在于确定“总数量”以及和总数量对应的总份数。在统计工作中,平均数(均值)和标准差是描述数据资料集中趋势和离散程度的两个最重要的测度值。
平均数在数学中可分为,算术平均数(arithmetic mean),几何平均数(geometric mean),调和平均数(harmonic mean),加权平均数(weighted average),平方平均数(quadratic mean)等。一般人大家所说的“平均数”就是算术平均数,即N个数字相加然后除以N。而“平均数”在统计学中包含三种:算术平均数、中位数、众数,都是用来描述数据平均水平的统计量。
- 算术平均数(Arithmetic mean):一组数据中所有数据之和再除以数据的个数。
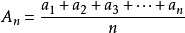
- 中位数(Median):将所有数值从高到低排列,最中间的数值。
栗子:1,2,3,4;排序后发现有4个数怎么办?
若有n个数,n为奇数,则选择第(n+1)/2个为中位数;若n为偶数,则中位数是(n/2以及n/2+1)的平均数。所以此例中位数为2.5。
- 众数(Mode):所有数字中出现频率最高的数值。
栗子:1,1,2,2,3,4的众数是1和2。如果所有数据出现的次数都一样,那么这组数据没有众数。例如:1,2,3,4没有众数。
通过公式我们可以看出:算术平均数易受极端数据的影响。中位数不受分布数列的极大或极小值影响,在一定程度上对分布数列的具有代表性。但缺乏数字敏感性,有些离散型变量的单项式数列,当次数分布偏态时,中位数的代表性会受到影响。众数不受极端数据的影响,而且具有明显集中趋势点的数值,能够代表整组数据的一般水平。在这三个平均数中,算数平均数是能够取得最大数字的平均数,所以,一般的统计调查都用的是这个做结论,比如平均工资。所以有时候大家会发现自己的工资“被平均”了,或者拖后腿了就是这个原因。2013年北京月平均工资5223元
结论:对于不同的统计平均值的方法,得出的数据结论是不一样的。有太多人利用本来正确的统计数据来穿凿附会得出自己需要的结果,有些原始的统计数据往往是由权威机构或人士做出的,只是被其他人赋予了原调查目的之外的其他意义。 所以一般见到平均数后,首先查明使用的是哪种平均数计算方法,然后试着用另外两种分析一下,看看是否有破绽。
更多资料推荐:
Applied Multivariate Statistical Analysis (豆瓣)
三、数据可视化如何说谎
统计数据的表现方法千差万别。虽然数据相同,但表述方式不同,呈现的效果也不同。
(1).图表长宽
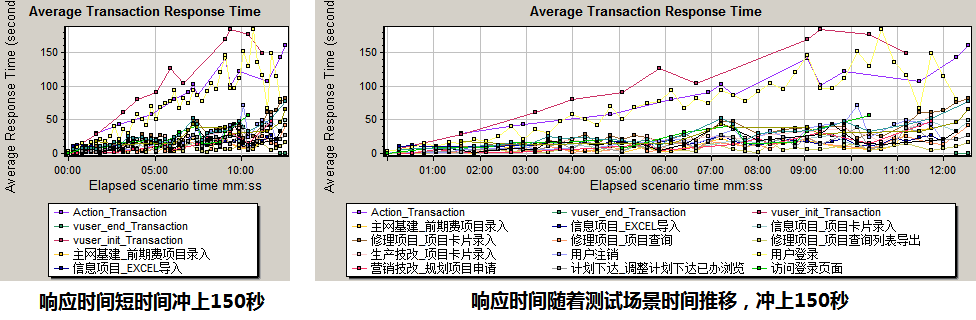
由《系统事务平均响应时间趋势图》可见,将图表的长宽比(长=横轴,宽=纵轴)从1:1拉伸到2:1后,数据发展趋势明显变缓。如果需要突出数据的爆发性增长,可以缩短时间间隔或记录次数(横坐标)。
- 左图暗示“系统事务平均响应时间在测试场景开始以后快速突破150秒”
- 右图暗示“系统事务平均响应时间随着测试场景执行时间延长逐渐增加”
(2).取值间隔
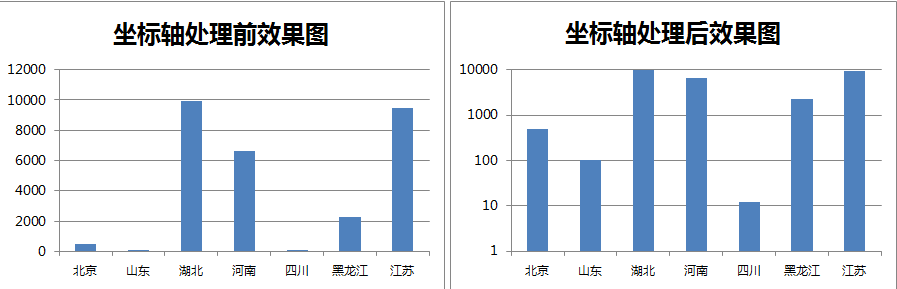
由上图可知,如果数据的取值间隔划分过大(等比数列1,10,100,1000,10000)而不是标准等差数列(1,2,3,4),则数据之间巨大差异会被缩小。
- 左图暗示“湖北、河南、江苏总产值排名前三远超其他省市”
- 右图暗示“各省市总产值相差并不太大”
(3).数据标准化
数据标准化也是归一化的过程。在数据分析之前通常需要先将数据标准化(Normalization),目的是去除奇异样本数据(相对于其他输入样本特别大或特别小的样本矢量),将数据按比例缩放,使之落入一个小的特定区间。或者去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权,而且能保正程序运行时收敛加快。
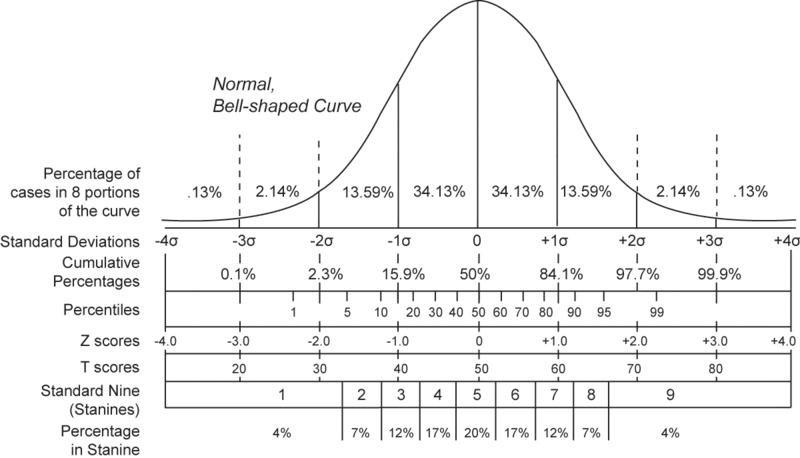
如上图所示,正态分布中的各类分段方法。包括: Standard deviations, cumulative percentages, percentile equivalents, Z-scores, T-scores, standard nine, percent in stanine.(Standard score)
数据标准化常用方法有“Min-max”、“Z-score”、“Atan”和“Decimal scaling”等。
- Min-max标准化(Min-max normalization)
适用于原始数据的取值范围已经确定的情况,缺点是当有新数据加入时,可能导致Max和Min值变化需要重新定义。设MinA和MaxA分别为属性A的最小值和最大值,将A的一个原始值x通过Min-max标准化映射成在区间【0,1】中的值,公式为:
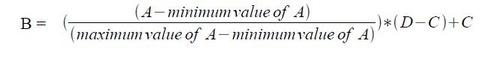
- Z-score 标准化(Zero-score normalization)
又名标准差标准化。经过处理的数据符合标准正态分布,均值为0,标准差为1。设μ为所有样本数据的均值,σ为所有样本数据的标准差。公式为:
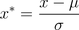
- Atan函数转换
使用这个方法需要注意的是如果想映射的区间为[0,1],则数据都应该大于等于0,小于0的数据将被映射到[-1,0]区间上。所以通过atan标准化会映射在区间【-1,1】上。
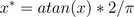
- 小数定标标准化(Decimal scaling)
通过移动数据的小数点位置来进行标准化,小数点移动多少位取决于属性A的取值中的最大绝对值。这个方法比较容易理解。
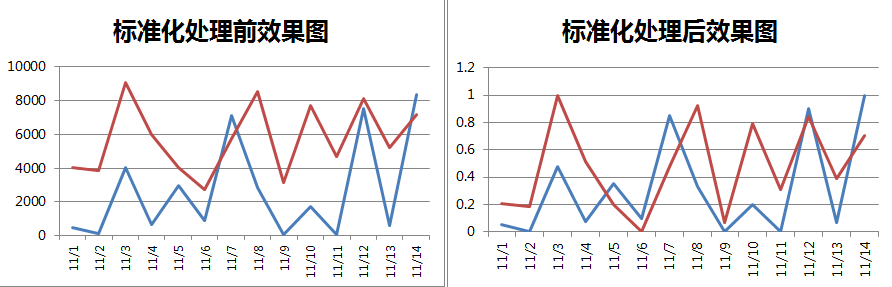
一个简单的例子对比如下图所示:
了解更多:
数据可视化经典例子:
四、结束语
数据如同金矿,需要人使用工具来开采、提炼、加工。
所以数据不会说谎,使用数据的人才会说谎;有些人是无意,有些人是蓄意。
祝每一个DMer都挖掘到金矿和快乐:)
参考文献:
[2].数据抽样方法(浙江大学《数据统计》)
[3].常见的“数据说谎”(TonySong,Webtrekk Business Consultant)
[5].《Asking The Right Questions:A Guide to Critical Thinking:学会提问-批判性思维指南》
[6].《How to Lie with Statistics:统计数字会撒谎》
[7].《Big Data: Pitfalls, Methods and Concepts for an Emergent Fielde》
[8].primary data and secondary data
[9].性能测试中常见的loadrunner analysis误导
[10].《Data Mining: Concepts and Techniques》, Jiawei Han and Micheline Kamber
[11].Data Normalization and Standardization
-----------2017年1月更新-----
专业在专栏:预见未来
多应景
有好事同志专门搞了一个网站来收集“八杆子打不着但看着贼拉靠谱的相关关系”,几乎就是专门让大家来扯淡装叉用的。
几个例子:
尼古拉斯凯奇在电影中的出镜次数和淹死在游泳池里的人数:
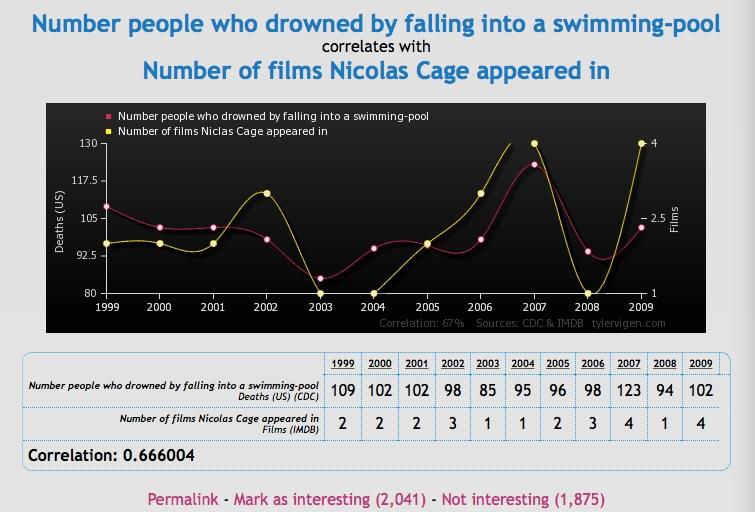
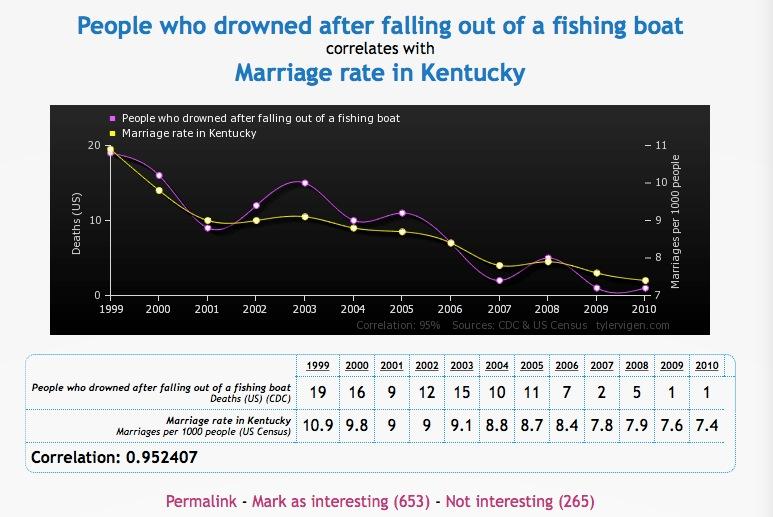
肯塔基州的结婚率和从渔船里掉出来淹死的人数:
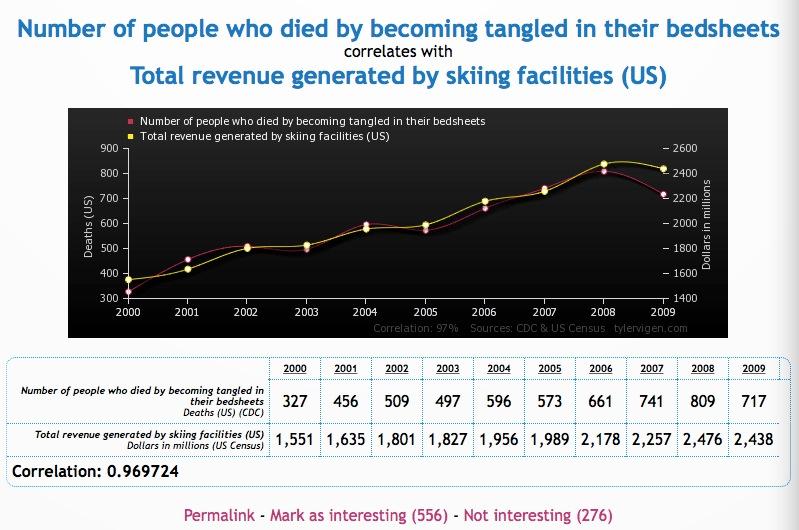
全美滑雪场的总收入与被床单缠住致死的人数:
所有例子图片都来自
20 Insane Things That Correlate With Each Other当奥巴马说“我国经济 09 年以来增长 13%”的时候,他没有告诉你其实美国人只有最富的 1% 收入增长了——剩下 99% 的人收入反而比之前
略微下降。
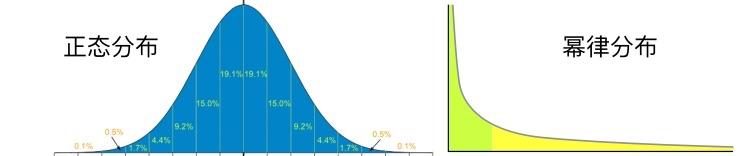
会出现这种情况是因为收入不是正态,而是
幂律分布的(即大家常说的 “20% 拥有 80% 的财富”)。所以最富人群的收入变化对经济总量影响最大,而剩下大多数人的收入变化对总量几乎没有影响。
举个具体的例子。假设有两个人,一个人有 100 块钱,一个人有 2 块钱。如果前者财富增长 10%(来到 110 块),后者减少 50%(来到 1 块),整个经济还是增长了 8%。
美国现在的情况就是这样,“经济整体复苏”但“多数人可支配收入没涨”。奥巴马夸自己经济政策有效确实没错,但特朗普、桑德斯也靠“拯救经济”的口号吸引了大量选民。这两个看似矛盾的事实其实都是对的。
幂律分布的数据在很多地方都会误导人。比如一家“成功” VC 的业绩其实
完全由所投公司中表现最好的一家决定。基金整体增长,只是因为投对了一家有 100 倍回报率的公司,而这家明星公司比该 VC 投的其他所有公司加起来都值钱。
--
另一种常见的“数据说谎”是调查问卷设计不合理。
英国政府 2015 年开始同意让父亲和母亲共休产假。但一年后的统计数据却显示,只有 1% 的父亲选择了休假。BBC、《卫报》等各大媒体报道之后
引发强烈社会反响。
真的是这样吗?
原来,这个 “1%” 的分母不是“有资格休假的父亲”,
而是“所有男性”。有人指出,如果这么算,即使当年所有新生父亲都选择休假,
调查得到的数字也只不过是 5%。
可以从调查结果中获利的商业机构就更不可信了。
之前有新闻说,一项对 2,000 人的调查发现,16 到 25 岁女性每周花 5 小时自拍——这听起来挺科学吧?但看过真正的调查报告之后你会发现,这个“5 小时”的数据没有涵盖“从不自拍”的女性。再仔细看,你会发现
这份调查是由一家美妆电商发布的,其目的可想而知。
除了在“分母”上做手脚以外,改变调查结果的方法还有很多。例如,不给出“其他”或“不知道”这类选项,问题题干加入误导性语言,调查对象有针对性选择等等。
一个很有意思的例子是,如果在问题中提到“奥巴马”(民主党执政八年的总统),更少的民主党人会说贫富差距过去八年变大了,而更多的共和党人会说过去八年经济变差了。简单地在题干中加上一个人名就改变了调查的结果。
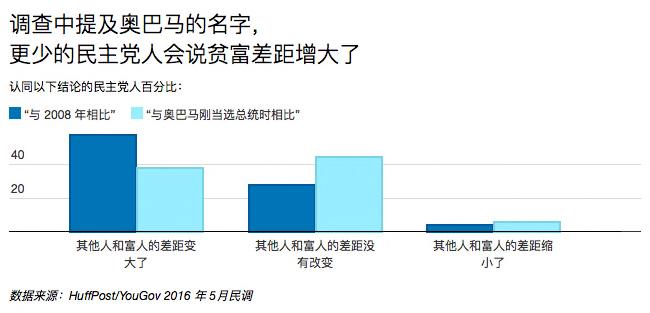
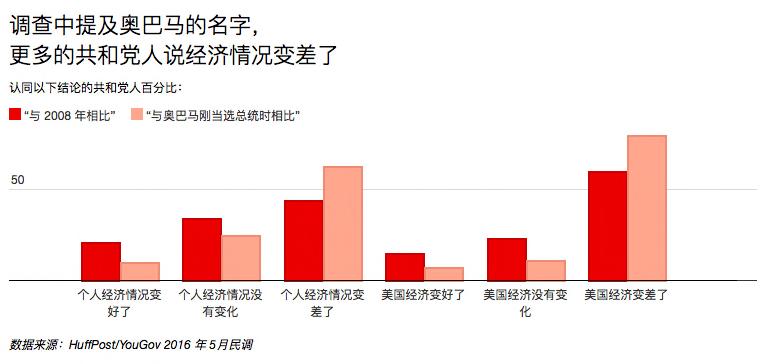
要说离我们更近的例子,可以参考
我之前写的这个回答——为什么一家民调说 59% 的台湾民众认为自己“只是台湾人,不是中国人”,而另一家却说 57% 有“泛中国认同”?
--
我想说的第三种“数据说谎”是暗示因果关系。
2015 年开始,英国卫生大臣亨特频繁引用
《英国医学会期刊》的一项研究,说周日住院的病人比周三住院的病人死亡率高 15%,每年英国有
6,000 到 11,000 人因为医院周末人手不足而死亡。
这听起来既科学、又可怕,对吧?
但问题在这里:虽然确有此研究,虽然这个 15% 的数字也是准确的,可这并不代表死亡率高就一定是因为医院周末人手不足。有没有可能周末住院的病人本身病情就比周中住院的重呢?(英国很多人平时可以请带薪病假。)在控制病人病情等其他因素之前,我们无法确定周日住院的死亡率高就一定是因为医院人手少。
卫生大臣亨特暗示这个因果关系也有他自己的原因——他所在的保守党竞选时承诺会增加公立医院周末员工数量,但因为保守党同时也削减了公共医疗开支(他们承诺会削减政府开支),所以必须要求年轻医生工作更长时间、照顾更多病人且不领加班费。由此一来年轻医生非常不满,亨特和他所在的保守党便希望通过这些数据来增加舆论对医生的压力。
另一个类似的问题是同工不同酬。你可以经常在奥巴马、希拉里的演讲中听到“做同样的工作,女性工资是男性 77%”这个数字。但是,“同工不同酬”引用的美国劳动统计部
报告第一页就写明他们“没有控制很多可能显著影响男女工资差异的因素”,比如工作时长,受教育程度,效率等。事实上,美国同种工作内的性别工资差异并不是因为雇主歧视,详细原因请看这里:
「男女同工不同酬」是事实,为什么公司不全部招聘女性,以获得同等的生产力并节约成本? - Yiqin Fu 的回答。
--
政治新闻看多了,各类“误导”方法很容易就积累一打:
GDP 数字漂亮的时候强调 GDP,通货膨胀数字好看的时候强调通货膨胀。夸自己就说“失业率低”,批评对手就说“失业率低只是因为很多人都不找工作了,所以没算在经济活动人口里面”。
绝对数字漂亮的时候强调绝对数字,百分比好看的时候强调百分比。希望增长的数字和去年相比有下降,那就和过去五年相比。希望下降的数字还在不停增长,那就说
“增长率下降”:
某地商品房连续四年的均价分别为 1 万、2 万、3.8 万、7 万。看到这组数据,你必定会大叫:天哪,房价真是涨得越来越厉害了!不过事实却恰恰相反:这四年的房价增长率竟在逐年降低。
不过也不仅是政客。只要是做 PPT 的行业,大家这种事都干过不少吧。
--
最后一类“数据说谎”我都不太好意思放在这里。如果前面只是误导的话,下面就是赤裸裸的谎言了。
例如特朗普转发的这张图片,信息来源“旧金山犯罪统计局”
根本不存在,数据也每个都是错的。(但居然在他转发九小时后就有 5,800 个赞和 7,700 次转发!)

所以再一次提醒大家:
不是只要带图带数字的就是真相!请仔细核查信息来源!不谈解读,很多数据本身就是错的。
最后送上一个饼图:
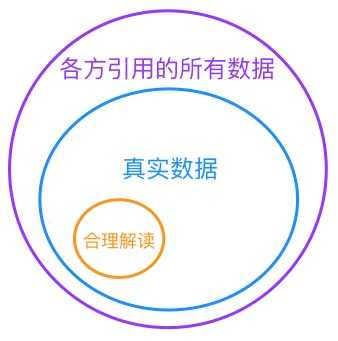
其他数据话题下的回答:
为什么有时候我们以为有很多人追的女生实际上不仅单身还没人追?如果「男女同工不同酬」是事实,为什么公司不全部招聘女性,以获得同等的生产力并节约成本?
