
建神经网络模型,哪种优化算法更好?
日期:2024-09-09 12:32 | 人气:
本文转载于建神经网络模型,哪种优化算法更好?35000次测试告诉你丨图宾根大学出品
想要优化自己的神经网络,却不知道哪种优化器更适合自己?
又或者,想知道深度学习中梯度下降的算法到底都有哪些?
现在,最全面的优化算法分析来了。
它整理了自1964年以来,几乎所有的优化方法 (约130种),将它们进行了分类。
此外,它还给出了几种基准测试方法,并用它分析了1344种可能的配置方案。
在运行了35000次测试后,它给出了非常全面的优化器算法分析介绍,并告诉你如何用这些基准测试,为自己的深度学习模型选择最好的优化方案。

论文题目:Descending through a Crowded Valley - Benchmarking Deep Learning Optimizers
论文地址:https://arxiv.org/abs/2007.01547
项目地址:https://github.com/SirRob1997/Crowded-Valley---Results
从下图这份密密麻麻的图表来看,迄今为止,提出的优化算法已经有130种左右。
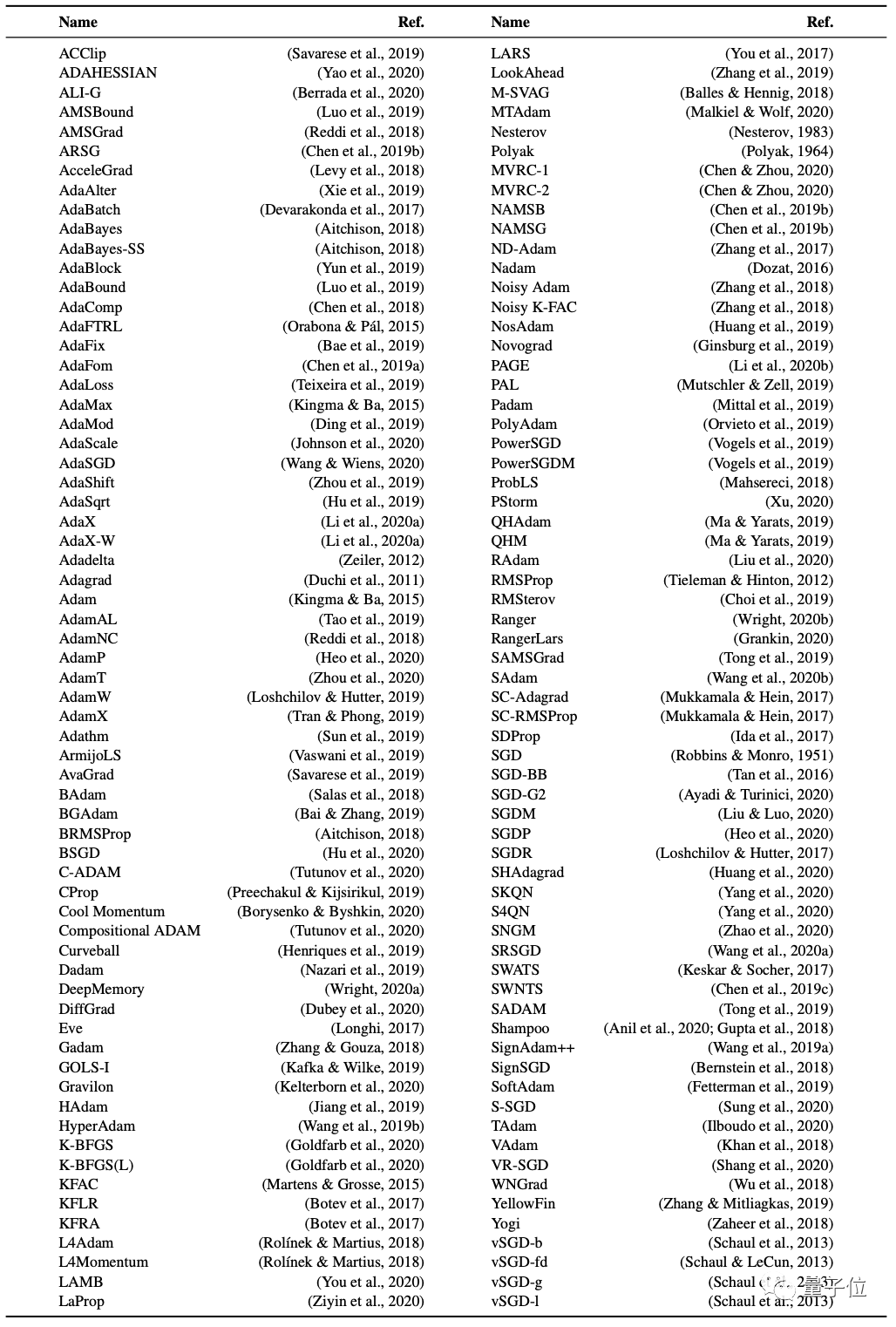
目前他们还看不出来区别,但在测试结果中可以发现,这些优化器明显能被分成两类,一种适用于VAE(变分自编码器),另一种则不适用于VAE。
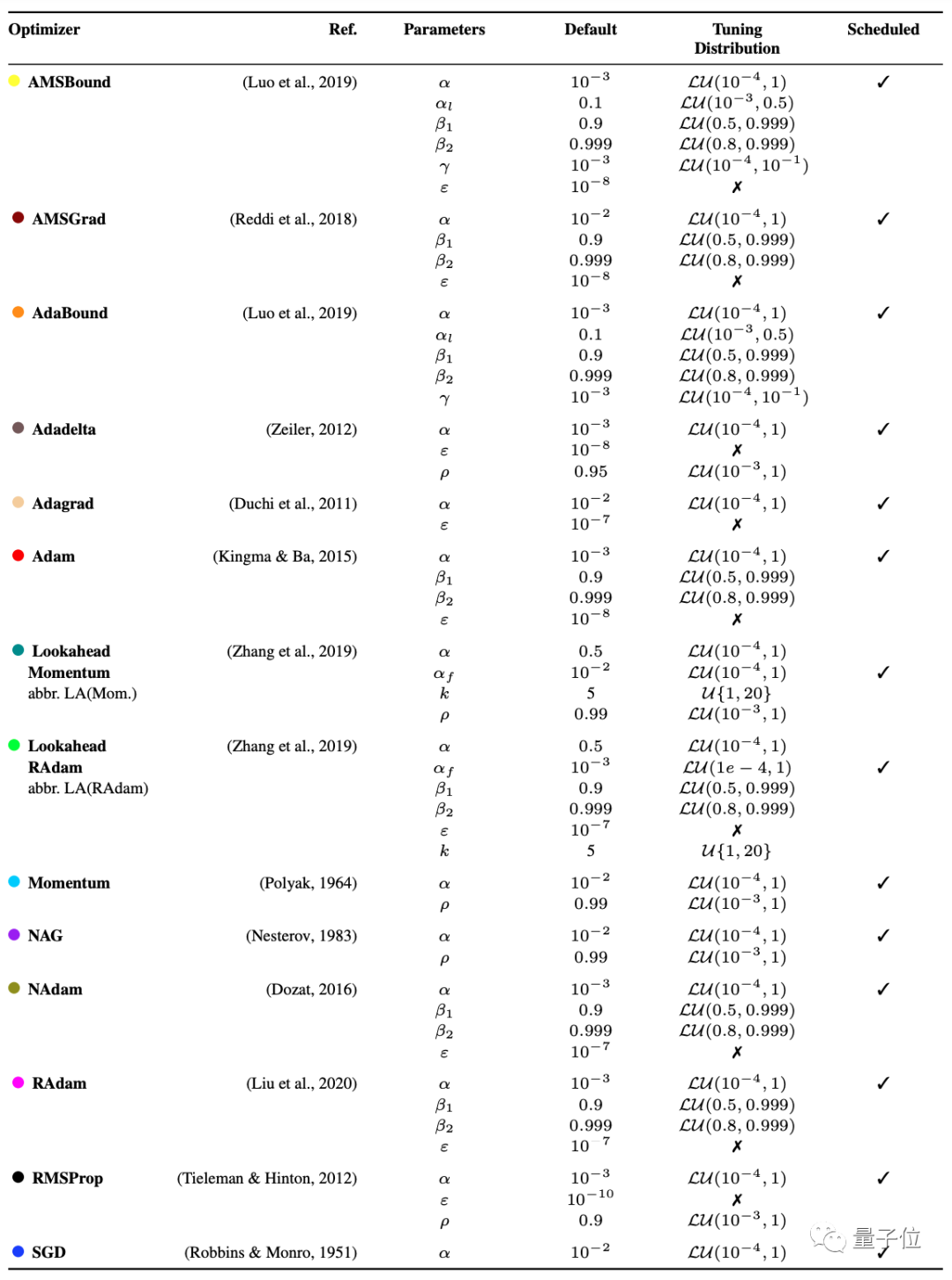
而从这些优化器中的常用参数来看,α0表示初始学习率,αlo和αup代表上下界,?t表示切换衰减样式的周期,k表示衰减因子。
可以看出,这些学习率的参数主要可以被分为常数、梯度下降、平滑下降、周期性、预热、超收敛等几种。
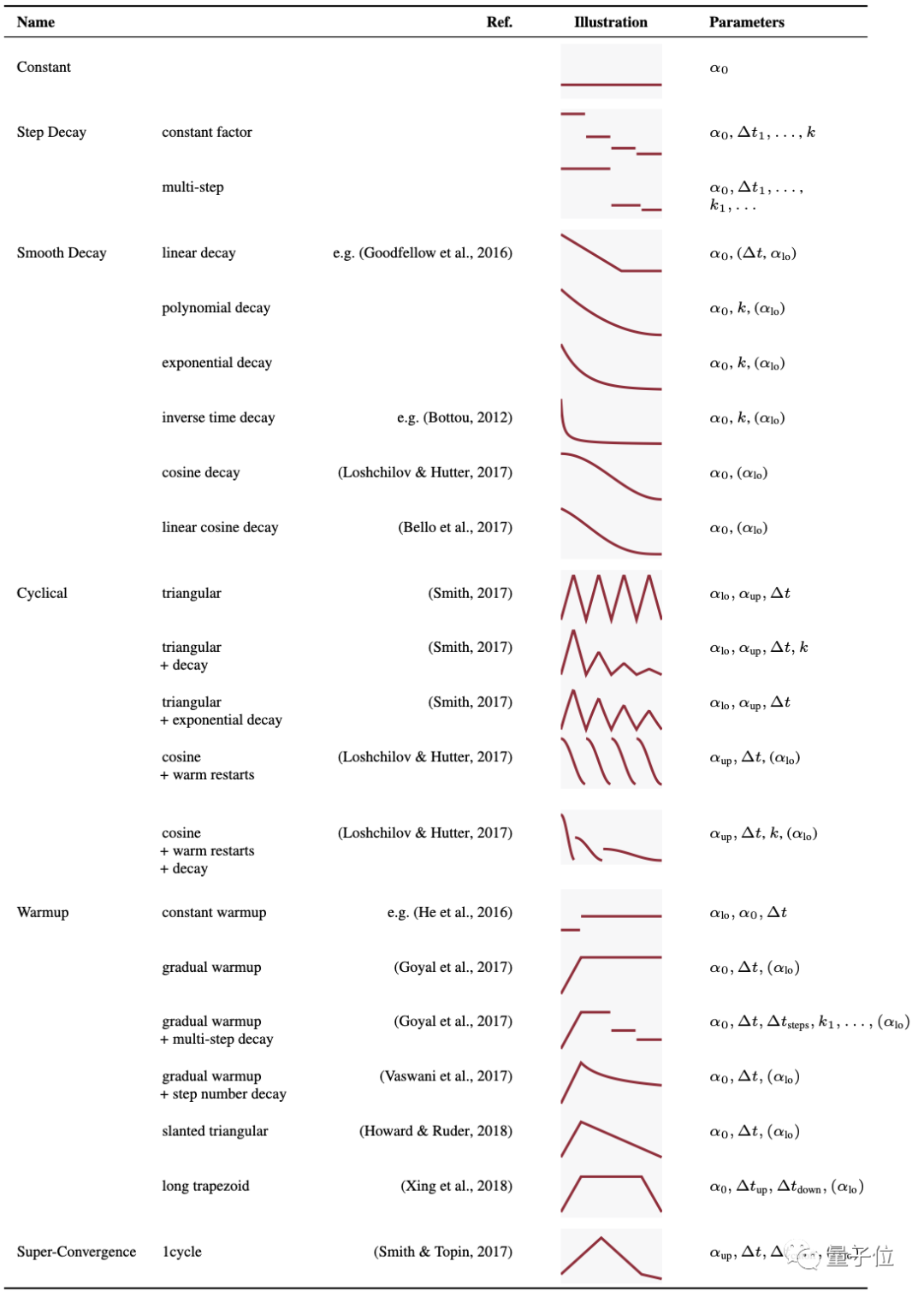
那么,130多种优化器,哪种才是最适用的?而对这些参数进行调整,到底能对优化器起到多大的作用?
用基准测试方法来测测,就知道了。
?
如下图,作者提出了8种优化任务,在这些任务上面进行测试,以得到对比结果。
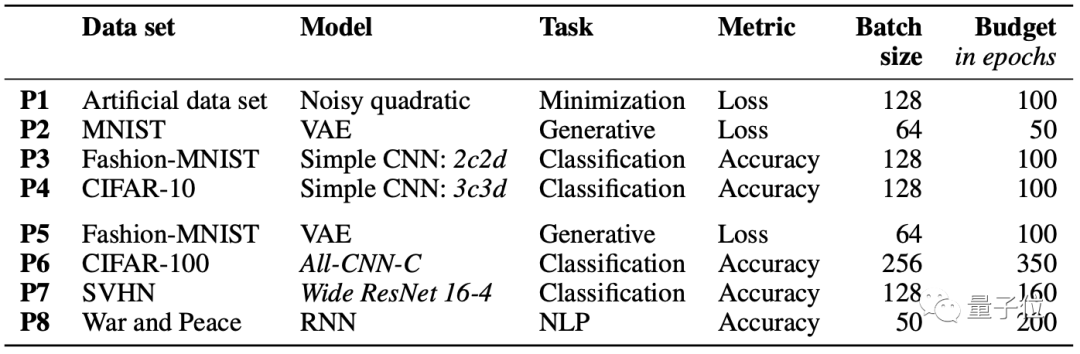
从图中看来,无论是数据集(MNIST、CIFAR-10等)、模型(VAE、CNN、RNN等),还是任务(分类、NLP等)和标准(损失率、精度)都不一样。
此外,batchsize也考虑在内(看来实验机器性能不错)。制作这些测试的目的在于,多角度考量出这些优化方法的合理性。
测试按照下图流程走,整体算下来,共有1344种配置,共运行接近35000次。
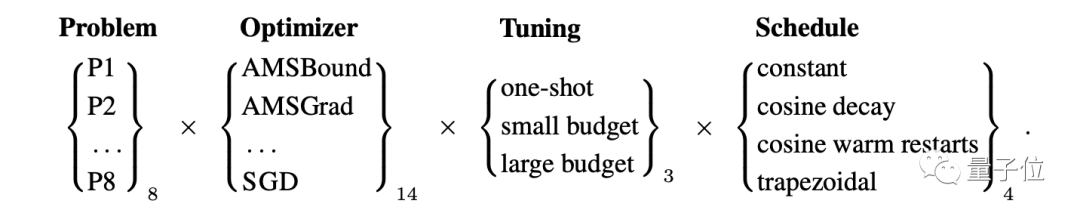
为了得知哪种优化方法更合适,这样做也是很拼了。
那么,具体如何选择适合的优化方法呢?
下图是作者随机选取的14个优化器。
下图是这些优化器在上面8种基准测试下的表现结果。

其中,红色的I表示误差范围。可以看出,在一定误差范围内,某一类优化方法的性能几乎非常相似:它们在各种基准测试上的表现都不错。
为了验证这些测试方法的稳定性,作者特意对其中一些算法进行了参数调整,下图是经典算法RMSProp和RMSProp(2)的调优结果。

可见,不同的参数能给优化算法的性能带来不小的波动变化。
更直接地,如果增加(性能)预算,从下图可以看出,性能的改进也会有所增加。(图中橙色为所有灰线的中值)
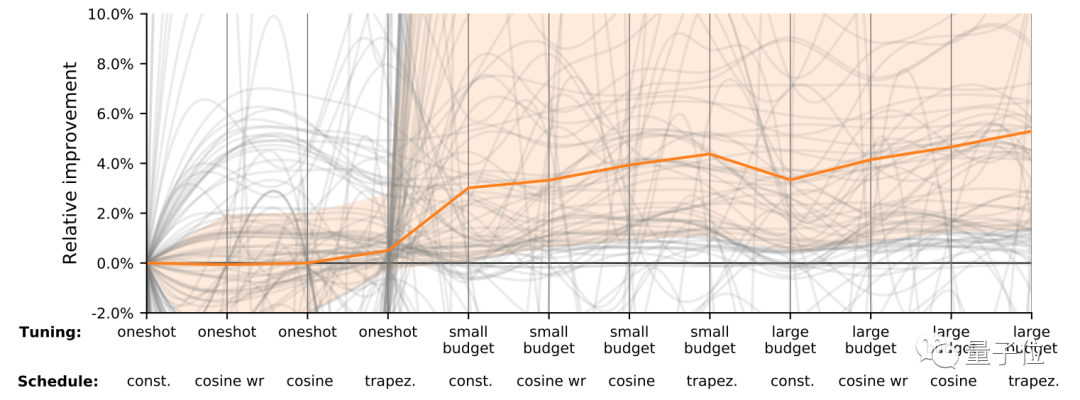
也就是说,即使优化算法的性能不错,合理调参仍然不可或缺。
那么,到底有多少优化器存在“改进参数,竟然能大幅增加优化能力”的问题呢?
还不少。
从下图来看,绿色表示优化过后,优化算法能更好地运行。
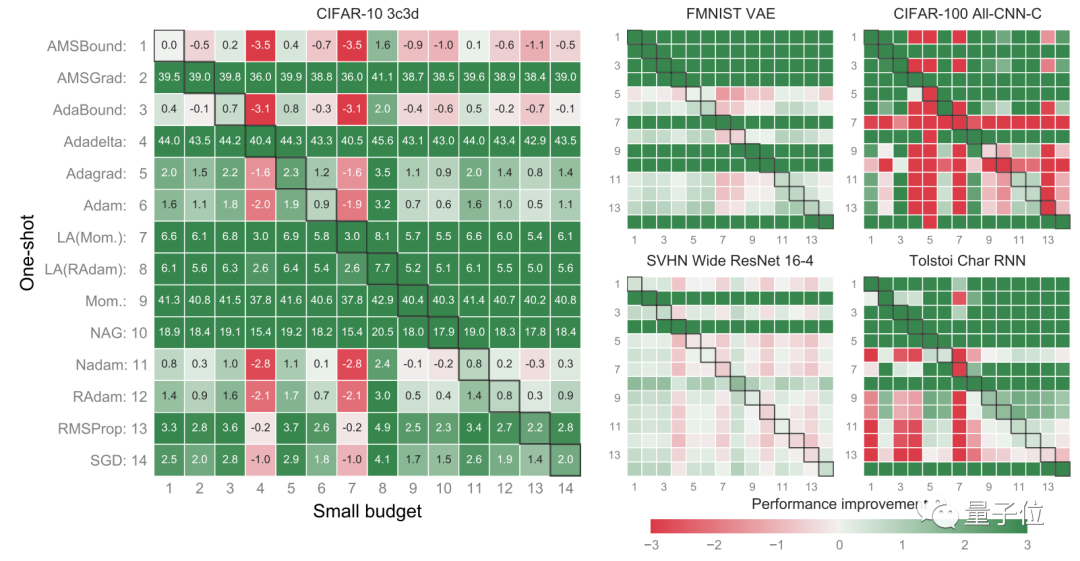
换而言之,只要某种优化算法的结果是一片绿,那么它原来的默认参数就真的很糟糕……
例如,AMSGrad、Mom、NAG的默认参数都存在很大的改进空间。相比而言,AMSBound由于自适应,默认参数都还非常不错,不需要再有大改进。
对这些优化器进行评估后,研究者们得出以下几个结论:
1、优化器的性能,在不同的任务中有很大差异;
2、事实上,大部分优化器的性能惊人地相似,目前尚没有“最通用”的优化方法;
3、对优化器进行(参数)微调,其实和选择优化器一样重要、甚至更重要。
不过,虽然这份表格已经非常详细,还是有细心的网友发现了盲点:像SWA这样非常简单高效的方法,还是在分析时被遗漏了。

当然,就提出的几种基准测试来说,已经适合用于分析大部分优化器的选择方案。
目前,作者已经在ArXiv论文页面,开源了基准测试方法的Code,感兴趣的小伙伴可戳论文地址查看~?https://arxiv.org/abs/2007.01547

