
神经网络架构之优化器和调度器详解
日期:2024-07-08 21:26 | 人气:
本文介绍使用优化器和调度器提升模型训练和调整超参数
优化器是神经网络架构的重要组成部分。调度器是深度学习工具的重要组成部分。
但是他们有什么方法来控制自己的行为呢?如何充分利用它们来调整超参数以提高模型的性能?
在定义模型时,需要做出一些重要的选择——如何准备数据、模型架构和损失函数。然后时必须选择优化器和调度器。
很多时候大多数项目选择可能是 SGD 或 Adam。
那么可以做些什么更有效地训练模型?
优化器由三个参数定义:
1优化算法,SGD、RMSProp、Adam……
2优化超参数,学习率、动量、……
3优化训练参数
本文探讨如何利用2和3。
首先回顾优化器在深度学习架构中的作用。
高层神经网络在训练期间经过多次迭代执行以下步骤:
1根据当前参数(即权重)和输入数据前向传递输出结果
2计算输出与目标输出之间的损失函数
3反向传播计算损失相对于参数的梯度
4使用梯度更新参数以减少下一次迭代的损失的优化
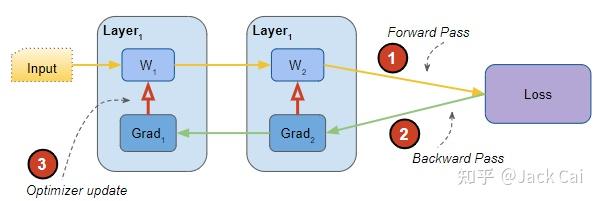
网络的组成部分和训练过程中的步骤
网络由层构成,每一层都有一些参数。 线性或卷积层具有权重和偏置参数。 还可以创建自己的自定义图层定义其参数。
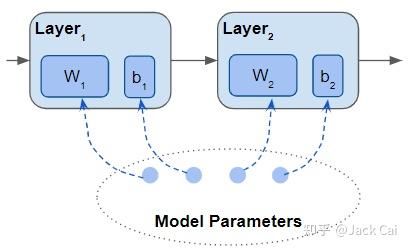
模型的参数是其所有层的所有参数
像 Pytorch 和 Keras 等框架有一个特定的数据类型来表示模型参数,即参数和可训练变量数据类型。
模型参数是张量,包含一个矩阵。 它们具有关联的梯度,每当对前向传递中的参数执行操作时,框架会自动计算微分。
每当定义了一种新类型的层时,无论是内置的还是自定义的,都可以使用此数据类型告诉框架应将哪些张量视为参数。
构建网络架构时,模型的参数包括该架构中所有层的参数。
创建优化器时,设置在训练期间更新的参数集。 包括模型的所有参数。
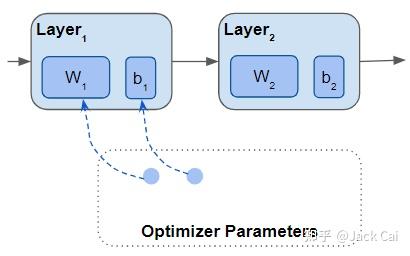
包含所有参数列表的优化器,该列表是模型参数的子集
在生成对抗网络 (GAN) 中,模型有两个优化器。 每个优化器只管理模型参数的一半。
训练开始时用随机值初始化这些参数。 然后在向前和向后传递之后,优化器会检查所有参数,使用基于以下值的更新值来更新每个参数:
1参数的当前值
2参数的梯度
3学习率和其他超参数值
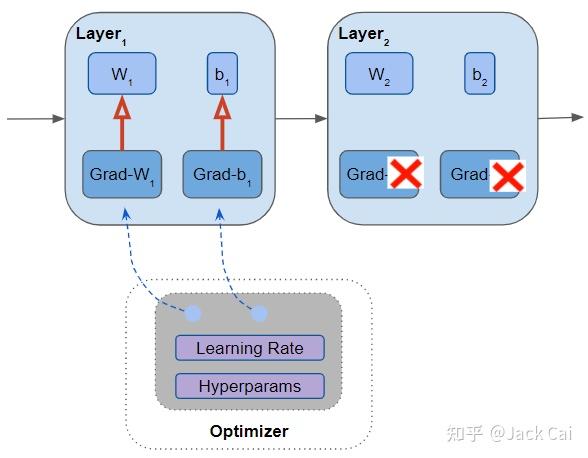
优化器更新所有参数
例如随机梯度下降优化器的更新公式为:

优化器不会计算其他模型的梯度。
所有优化器都需要超参数。 其他超参数取决于使用的特定优化算法。如,基于动量的算法需要一个“动量”参数。 其他超参数可能包括“beta”或“权重衰减”。
创建优化器时,需要为优化算法的所有超参数提供值(或使用默认值)。
选择的超参数值对训练的速度以及模型性能有很大影响。
由于超参数非常重要,因此神经网络可以对设置它们的值进行很多细粒度的控制。
从广义上讲可以控制两个轴。 第一个涉及参数组。接下来进行介绍
某些网络的超参数只有一组值。 但是如果想为网络的不同层选择不同的超参数怎么办?
参数组可以做到。 可为网络定义多个参数组,每个参数组包含模型层的子集。
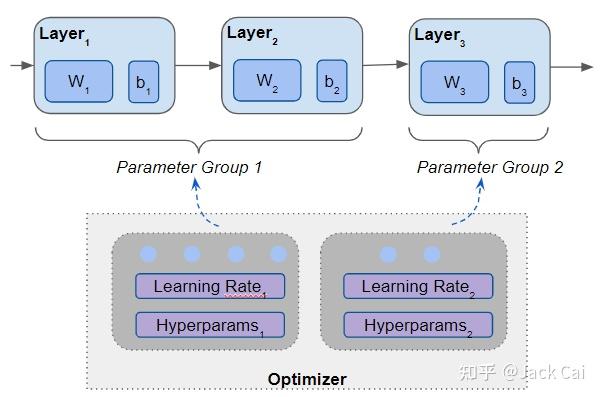
模型的不同层可以放在不同的参数组中
现在可以使用这些为每个参数组选择不同的超参数值。 称为差异学习,即不同的层“以不同的速率学习”。
应用差分学习的一个常见用例是迁移学习。 迁移学习是计算机视觉和 NLP 应用流行的技术。 本文使用一个预训练模型,如使用 ImageNet 数据集进行图像分类,然后将其重新用于小图像。
执行此操作时,重用所有预先学习的模型参数,且仅针对数据集对它们进行微调。
在这种情况下将网络拆分为两个参数组。 第一组由提取图像特征的所有 CNN 层组成。 第二组由作为这些特征的分类器的最后几个线性层组成。
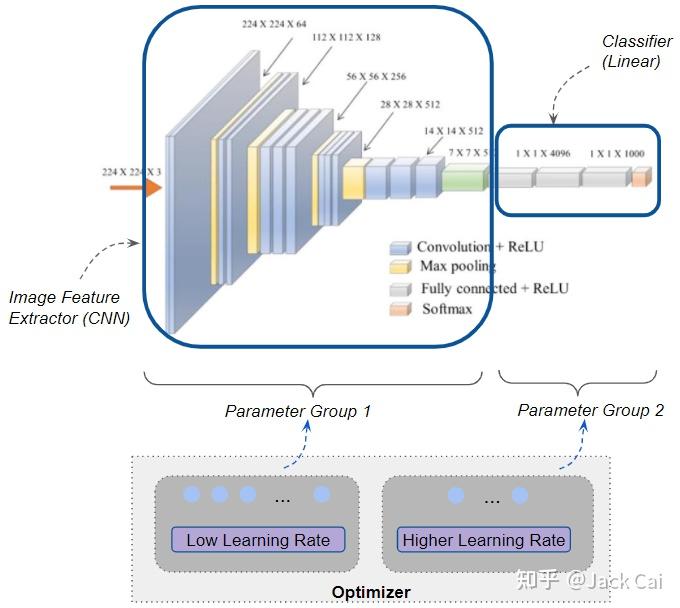
使用图像分类器进行迁移学习。 CNN 层和线性分类器层具有不同的学习率。
CNN 层学到的图像特征的大部分内容也适用于应用程序的图像。 因此可以使用非常低的学习率来训练第一个参数组,从而使权重变化很小。
可以对第二个参数组使用更高的学习率,以便分类器学习区分新图像而不是原始的类别。
Pytorch 的优化器提供了很大的灵活性,可以为每个组量身定制参数组和超参数。
Keras 没有对参数组的内置支持。 必须在自定义训练循环中编写自定义逻辑,以这种方式使用不同的超参数对模型的参数进行分区。
刚刚看到了如何使用参数组调整超参数。 对超参数调整进行细粒度控制的第二个轴涉及调度程序的使用。
到目前为止已经介绍了超参数。 那么如果想随着训练的进行改变超参数值怎么办?
这就是调度器的用武之地。可以根据训练时期调整超参数值。称为自适应学习率。
有使用各种数学曲线来计算超参数的标准调度程序算法。 Pytorch 和 Keras 有几个流行的内置调度程序,如指数、余弦和循环调度程序。
选择要使用的调度程序算法并指定超参数值范围的最小值和最大值。 在每个训练时期开始时,算法使用最小/最大范围和时期数来计算超参数值。
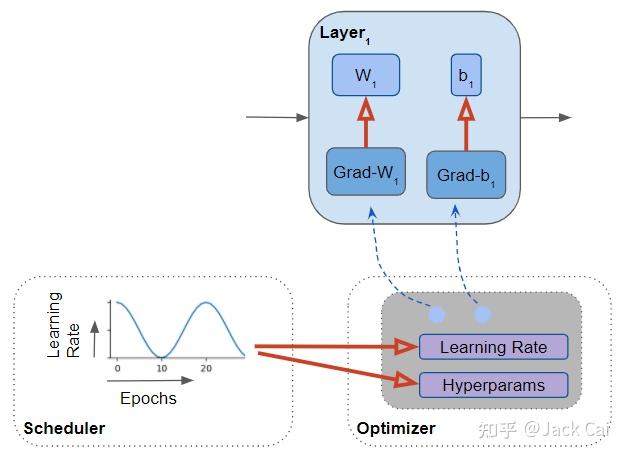
调度器修改每个训练时期的学习率和超参数值
调度器是一个单独的组件,是模型的一个可选部分。 如果不使用调度程序,则默认超参数值在整个训练过程中保持不变。 调度器与优化器一起工作,而不是优化器本身的一部分。
现在了解了在训练期间可以控制超参数值的不同方式。 最简单的技术是为模型使用单个固定学习率超参数。 最灵活的是沿两个轴改变学习率和其他超参数——不同层的不同超参数值,并在训练周期的过程中随着时间的推移同时改变它们。
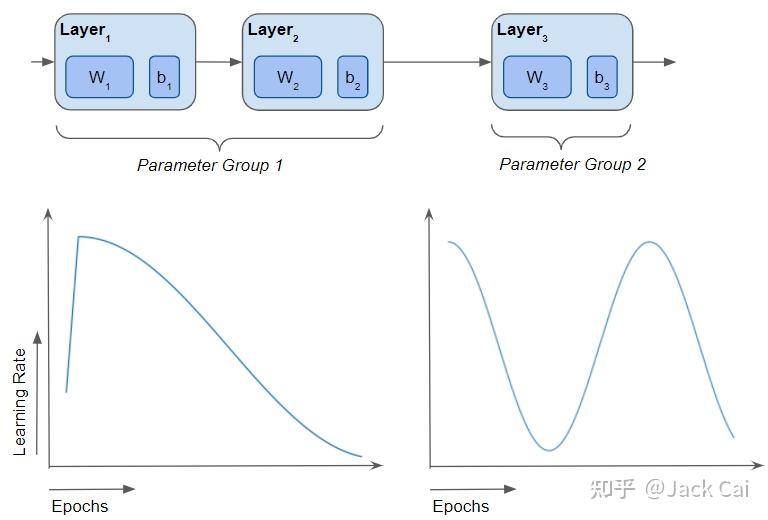
针对不同层以及基于训练时期改变超参数
读者可能会读到一些优化算法(如 RMSProp)根据这些参数的梯度为不同的参数选择不同的学习率。
这是那些优化算法的内部,由算法自动处理。 设计模型时它是不可见的。 学习率基于梯度而不是基于训练时期而变化,就像调度器的情况一样。
因此不要将两者混淆。
本文介绍了优化器和调度器的作用,以及它们提供的功能,能够增强模型。
Pytorch 和 Keras 包含相关的内置函数。
欢迎关注

